Uploading a large zip file to Moodle succeeds, but extracting it inside a File resource fails with a generic error. The reason is that Moodle retains the original archive while unpacking, so extraction requires temporary space equal to the zip plus its uncompressed contents — and this combined size is checked against the course-level upload limit.
The three-layer limit stack
Moodle enforces file size limits at three levels, and all three must
be satisfied:
PHP (upload_max_filesize,
post_max_size in php.ini) — governs the
initial HTTP upload.
Site ($CFG->maxbytes, set in
Site administration > Security > Site security
settings) — the global ceiling.
Course (per-course maximum upload size, inherited
from the site default unless overridden) — applied when files are used
inside the course context.
Most administrators raise the PHP and site limits when large uploads
are needed. The course-level limit is easy to miss.
Why the math catches you out
Consider a 600 MB zip file containing a large SCORM package or video
collection. The actual uncompressed size is also approximately 600 MB.
During extraction:
The zip file remains on disk: 600 MB
The extracted files are written alongside it: 600
MB
Peak combined usage: ~1.2 GB
If the course upload limit is 1 GB, extraction fails. The upload
succeeded because 600 MB is under 1 GB. The extraction fails because 1.2
GB is not.
The error message Moodle shows — something like “Cannot unzip file” —
does not explain this. It looks identical to a corrupt zip or a
permissions error.
Finding which limit is
triggering
Check the course-level limit first. In the course settings:
Course settings > Files and uploads > Maximum upload size
If this is set to “Site upload limit” rather than a specific value,
check the site limit:
Site administration > Security > Site security settings > Maximum uploaded file size
The effective limit is the minimum of all three. The course limit is
the one most likely to be set too low.
The fix
Temporarily increase the course upload limit to at least twice the
zip file size before attempting extraction:
Course settings > Files and uploads > Maximum upload size > Set to 2 GB (or higher)
Save, extract the zip in the File resource, then reduce the limit
back to a sensible value.
If the site limit is the bottleneck, raise it temporarily in:
Site administration > Security > Site security settings > Maximum uploaded file size
Do not leave an inflated limit in place permanently — it affects all
courses on the site.
Avoiding the problem
For very large archives, consider unpacking on the server directly
rather than through the Moodle interface. Upload the zip via SFTP,
extract it into the correct moodledata path, and use
php admin/cli/files_refresh.php or the file repair tool to
register the files. This bypasses all three upload limits entirely.
Alternatively, for SCORM packages specifically, some authoring tools
can produce smaller packages by splitting large assets (video) out of
the SCORM zip and referencing them as external resources.
Moodle already contains useful data about student engagement: course access, activity completion, grades, and discussion activity. The difficulty is that this data is often scattered across reports, or surfaced through analytics tools that teachers may not fully trust because the reasoning behind a warning is not always obvious.
To solve this, we built Solin Early Warning. It is a Moodle block (a small panel that appears on the side of a course page) that pulls relevant signals into a ranked list directly inside the course. Instead of pushing opaque alerts or automated emails, it uses a multi-signal architecture to tell you exactly why a student was flagged, right where you need to see it.
This guide explains how the heuristics work, the research behind them, and how you can tune the settings for your own courses.
Before you start: Completion tracking
Before the block can use all of its signals, your course needs activity completion tracking enabled. Two signals depend on this: assessment miss and stalled completion.
For the assessment-miss signal to work, the relevant activities also need an “Expect completed on” date configured. If completion tracking is not enabled in your course, the block will still run using inactivity, grade trend, and optional forum silence, but it cannot tell whether students are missing expected activity completions.
The research: Architecture over magic numbers
The most authoritative public guidance on early warning systems (such as the 2018 NCES Forum Guide) explicitly states that universal “default” thresholds do not exist. What counts as at-risk in a short compliance module is very different from a 14-week university semester.
For this reason, Solin Early Warning provides a research-informed architecture with institution-tunable thresholds. The combination of signals is backed by empirical literature, but the exact numbers are conservative starting points that you are expected to tune.
To make this distinction visible, every default in the next section is labeled with its evidence type:
Strong empirical: the signal or threshold is directly supported by published studies.
Institutional convention: the most common starting value across documented practitioner sources, but not directly empirically validated.
Conservative starting point: a reasonable default that you should expect to tune for your context.
Contested: the empirical literature disagrees about whether the signal predicts what we think it predicts.
How the 5 signals work
The block evaluates students against five independent signals. If a student triggers any of these signals, they appear in the block.
1. Inactivity (Default: 7 days)
How it works: Flags a student if they have not accessed the course in the last 7 days.
The research: The signal itself is well supported (course access is a basic engagement indicator across the literature). The 7-day threshold is institutional convention: a 7 to 15-day window is the most common starting value in higher-education practitioner sources.
Configuration advice: For short, fast-paced courses, tighten this to 3 or 5 days. For long-cadence or self-paced courses, widen it to 14 days or more.
2. Assessment miss (Default: 14-day window)
How it works: Flags a student who has not completed an activity whose expected completion date fell within the last 14 days. This applies to assignments, quizzes, SCORM packages, lessons, H5P activities, graded forums, and any other Moodle activity that uses completion tracking.
The research: Strong empirical support for the signal itself. Open University (OU Analyse) research shows that students who miss the first Tutor Marked Assignment have a very high probability of course failure; LAK 2025 confirms missed-deadline behavior as a strong predictor across more than 50,000 assignments. The 14-day window is a conservative starting point and is not itself empirically optimized.
Caveat: The signal uses the activity-level expected completion date. It does not yet account for per-student extensions (such as quiz access overrides or assignment user-flag extensions). A student given an extra week on Quiz 3 will still be flagged as “not completed” while their override is active.
3. Negative grade trend (Default: Enabled)
How it works: Flags a student whose course total grade has trended downward for two consecutive weeks. This signal only becomes available after the block has collected enough weekly grade snapshots.
The research: The broader literature supports academic performance and negative momentum as useful risk indicators, but the empirical evidence does not validate any specific delta or interval. We deliberately do not require a percentage drop. The “two consecutive weeks” rule is a conservative starting point.
4. Stalled completion vs peers (Default: Bottom quartile in 14 days)
How it works: Flags a student who is in the bottom 25% of the class for completing activities over the last two weeks.
The research: The Purdue Course Signals project made peer-relative activity a central part of its early-warning model, and the JISC case study identified it as a key differentiator from absolute-threshold systems. The idea is simple: a student’s activity level is easier to interpret when compared to the actual pace of the class. The specific “bottom quartile in 14 days” rule is a conservative starting point.
How it works: Flags a student with zero forum posts in the last 14 days, provided the rest of the class is actively posting.
The research: Contested. Some studies find forum participation significantly predictive; Rogers et al. (2025) find a weak negative correlation with academic performance. Vendor systems like Brightspace treat it as a core indicator, but that assumes forums are structurally central to the course pedagogy.
Configuration advice: Because of the contested evidence, this signal ships disabled. A site administrator can enable it under Site Administration → Plugins → Blocks → Solin Early Warning. Once enabled site-wide, individual teachers can override it per course (force on, force off, or inherit the site default) via the block’s gear icon. Only enable it if discussion forums are central to your course pedagogy.
How configuration works
Solin Early Warning has three layers of configuration, in order of reach:
Site-level defaults. Set by a site administrator under Site Administration → Plugins → Blocks → Solin Early Warning. These are the institution-wide defaults every block instance starts from.
Per-block-instance overrides. A teacher with the right capability can override site defaults for a specific course by clicking the gear icon on the block. The configuration form is explicit about what is overridden and what is inherited (it shows “Inheriting site default: 7 days” rather than just “7 days” so it is obvious when an institution-wide change will affect this course).
Inline sensitivity preset. The “Show: More / Default / Fewer” dropdown on the block header. This is the fastest way to recalibrate without leaving the course. It writes to the per-block-instance configuration, so a teacher’s preset persists across visits.
Most teachers will only ever use layer 3. Most administrators will only ever set layer 1.
Context matters: Percentiles, small classes, and calibration
Raw data is useless without context. The block includes specific features to make sure the flags make sense in the real world.
Peer-percentile rank and small classes
Next to every flag, the block shows the student’s percentile rank compared to their peers. If a student has not logged in for 9 days, the block will also tell you if that puts them in the bottom 10% of the class.
However, peer-relative signals need a meaningful peer group. In very small courses (fewer than 10 active enrollments), the block will automatically disable peer-relative signals because a single student can distort the comparison. In classes between 10 and 19 students, the block will show a caveat advising you to interpret the peer comparison with care.
The 4-week calibration window
Empirical studies repeatedly show that the first 3 to 5 weeks of a course are the highest-signal window for predicting dropouts.
Weeks 1 and 2: The block only flags students who have not accessed the course at all yet. Other signals are still gathering data.
Weeks 3 and 4: All enabled signals run, but flagged students are marked with a “Tentative” badge. This allows teachers to see the heuristics calibrating during the period when early intervention matters most.
Week 5 onward: The tentative badge is removed and the block runs with full confidence.
If you install the block on a course with no enrolled students, the block will say “Heuristics will activate when students enroll”. This is expected behavior, not a bug.
Holidays and term breaks
Time-based signals would otherwise produce a flood of false positives during institutional breaks: every student looks “inactive” during winter break, and any activity scheduled across the break window appears “missed”. The block handles this in three ways:
Site-level breaks calendar. A site administrator can declare institution-wide break ranges (Christmas, spring break, summer holidays) under the block’s site settings. Time inside those ranges is discounted in time-based calculations, so a holiday does not make students look inactive simply because the course was paused. Activities whose expected completion date falls inside a break are excluded from the assessment-miss signal.
Per-course break ranges. A teacher can declare ad-hoc break ranges for a specific course via the block’s gear icon. These add to the site-level list. Use this for course-specific pauses that do not apply institution-wide.
Pause for one week. A “Pause for one week” link in the block header is available to teachers and adds a one-week break to the current course. A “Resume now” link appears in the active-break banner if you need to end the pause early.
When the current render time falls inside a configured break, the block shows a banner explaining that the list reflects pre-break activity. When past breaks are dampening the current numbers, the block shows a small note explaining how many days of break time were excluded. The flagged list is never hidden during a break — it stays visible so a teacher preparing for resumption can see what is queued up.
Day-to-day use for teachers
The block is designed to be scannable and actionable within seconds.
Reading severity: A student who triggers exactly one signal gets a Yellow “Watch” label. A student triggering two or more signals gets a Red “At risk” label. The list automatically sorts the most severe cases to the top.
Adjusting sensitivity: Teachers will not use a tool that floods them with noise. In the block header, there is a “Show: More / Default / Fewer” dropdown. This allows you to instantly recalibrate the block for your course without opening the settings form. “More” adjusts the thresholds in the direction that shows more students. “Fewer” only shows the clearest cases.
Setting
More (shows more students)
Default
Fewer (shows fewer students)
Inactivity
5 days
7 days
14 days
Assessment-miss lookback
21 days
14 days
10 days
Forum-silence lookback
10 days
14 days
21 days
Grade trend
unchanged
unchanged
unchanged
Stalled completion
unchanged
unchanged
unchanged
The release valve (Dismiss for one week): If a student is flagged but you know the situation is already explained (for example: illness, a planned absence, or a temporary extension), you can click “Dismiss for one week”. The student is hidden from the list for 7 days. After that, they will reappear only if they still trigger one or more signals.
What about Moodle’s built-in analytics?
Moodle includes a Learning Analytics tool with a “students at risk” model. It is a different design choice: it uses a machine-learning backend (Python in current versions, PHP in older versions) to predict dropout probability, and pushes alerts via email. It can suit institutions that are prepared to maintain the required analytics setup and that prefer push notifications.
Solin Early Warning takes a different approach: in-course visibility, transparent heuristics rather than ML, no email blasts, and an explicit per-signal explanation for every flag. Both can run on the same site. They answer different questions.
What this block does not do
Solin Early Warning does not predict dropout probability, and it does not replace teacher judgment. It does not use demographic profiling, student-background data, or a machine-learning model. It only uses observable Moodle course data and shows the reason for each flag.
A flag means: this student is worth checking. It does not mean: this student will definitely drop out.
Research behind this guide
The signal design and initial configuration defaults of the Solin Early Warning block are informed by the following sources:
Solin Early Warning is designed to make risk signals visible inside Moodle. For institutions that want a broader view across courses, Solin can also help review engagement patterns and tune the thresholds to the shape of your courses.
Certbot stores the webroot path it used during initial certificate issuance. If you later move Moodle's document root — for example, when separating the codebase from the data directory — Let's Encrypt HTTP challenge requests hit a 404 and auto-renewal fails silently until the certificate expires.
How Certbot’s webroot
validation works
The HTTP-01 challenge works by placing a temporary token file at:
/.well-known/acme-challenge/<token>
Let’s Encrypt then fetches that file over HTTP to prove you control
the domain. Certbot writes the token to a directory on disk and the web
server serves it. The directory it writes to is recorded when the
certificate is first issued and stored in the renewal configuration
file.
If the web server’s document root has changed since then, the file is
written to the old path, the web server cannot find it, and Let’s
Encrypt gets a 404. The renewal fails.
Diagnosing the problem
Run a dry-run renewal to see the error without modifying
anything:
certbot renew --dry-run
A failing renewal will show output like:
Attempting to renew cert (yourdomain.com) via certbot...
Challenge failed for domain yourdomain.com
http-01 challenge for yourdomain.com
Cleaning up challenges
Failed to renew certificate yourdomain.com with error:
Some challenges have failed.
Check the current webroot path Certbot has on record:
cat /etc/letsencrypt/renewal/yourdomain.com.conf
Look for the webroot_path value under
[webroot_map]:
If the dry-run succeeds, the next scheduled renewal will work
correctly.
Alternative: re-run
certificate issuance
If you prefer not to edit the config file manually, you can re-run
Certbot’s webroot mode, pointing it at the new path. This updates the
stored configuration as a side effect:
Use --force-renewal only in this recovery scenario — it
counts against Let’s Encrypt’s rate limits.
Checking
that the challenge path is web-accessible
Before the dry-run, verify the web server can actually serve from
/.well-known/acme-challenge/. On Apache, the default
WordPress or Moodle .htaccess sometimes redirects all
requests to index.php, which blocks the challenge path.
Check for a rule like this in your .htaccess:
RewriteRule ^ index.php [L]
If present, add an exception before it:
RewriteRule ^\.well-known - [L]
On Nginx, verify there is no try_files or
return directive that catches all requests before the
challenge path can be served.
Automating renewal checks
Certbot installs a systemd timer or cron job for auto-renewal, but
failures are only logged — no alert is sent by default. Add a simple
check to your monitoring:
Or use ssl-cert-check to get an alert before the
certificate reaches a critical expiry window.
Every file Moodle serves goes through PHP by default. On sites with large video files or a high number of concurrent downloads, this ties up PHP-FPM workers for the duration of each transfer. Enabling X-Sendfile transfers that work to the web server, freeing PHP instantly.
Why PHP file serving is a
bottleneck
When a user accesses a file in Moodle — a video, a PDF, a SCORM
package — the request goes to pluginfile.php. Moodle checks
permissions, resolves the file from moodledata, and streams
it back to the browser. While the download is in progress the PHP-FPM
worker is occupied: it cannot serve other requests.
A single 500 MB video streamed to a user on a slow connection can
hold a PHP worker for 10–20 minutes. On a site with a limited FPM pool,
a handful of concurrent video viewers can exhaust all available workers,
making the entire site unresponsive.
How X-Sendfile works
X-Sendfile is a mechanism where PHP sets a response header instead of
sending the file body. The web server intercepts that header, locates
the file on disk, and streams it directly to the client. PHP exits
immediately — the FPM worker is released.
The header name differs by web server: – Apache:
X-Sendfile (requires mod_xsendfile) –
Nginx: X-Accel-Redirect
Moodle has built-in support for both.
Apache configuration
Install mod_xsendfile if it is not already present:
In your virtual host configuration, declare the paths that Apache is
allowed to serve via X-Sendfile:
XSendFile On
XSendFilePath /var/moodledata
XSendFilePath /var/www/moodle
The path must match the real filesystem path of
moodledata and, if your theme or plugin serves files from
the Moodle root, the Moodle directory as well.
Nginx configuration
Add an internal location block that maps to your moodledata
directory:
location /moodledata-internal/ {
internal;
alias /var/moodledata/;
}
The location name is arbitrary — it just needs to match what Moodle
will put in the header.
Without X-Sendfile the response body comes directly from PHP. With
X-Sendfile the PHP response will have Content-Length: 0 and
the X-Sendfile header will be present (stripped by the web
server before sending to the client, but visible in debug mode).
A simpler check: watch FPM worker utilization during a large file
download with
watch -n1 'php-fpm8.2 -t 2>&1; ps aux | grep php-fpm | grep -v grep | wc -l'.
Without X-Sendfile the count stays elevated for the duration of the
download. With X-Sendfile the worker count drops back to baseline within
seconds.
Caveats
moodledata must not be web-accessible directly.
X-Sendfile only works because Moodle’s PHP code runs first to enforce
access control. The web server then serves the file after PHP has
authorised it. Never point a public Alias or
root directly at moodledata.
Symlinks: if moodledata contains
symlinked directories (some backup or filedir configurations do this),
ensure mod_xsendfile or Nginx is configured to follow them,
or the file lookup will fail.
PHP memory: X-Sendfile also eliminates the memory
overhead of reading the file into PHP before sending. This is
particularly relevant for ZIP files or large SCORM packages where PHP
would otherwise buffer the entire file.
When a Moodle scheduled task crashes mid-run, the lock it held can persist indefinitely, blocking every subsequent run. This guide explains how Moodle's task locking works, how to identify a stuck task, and how to clear it without disrupting active tasks.
How Moodle task locking
works
Every scheduled task and ad-hoc task acquires a lock before it runs.
By default Moodle uses a file-based lock factory: it creates a lock file
inside moodledata/lock/ named after the task. While the
lock file exists, no other process can start the same task.
When a task finishes normally it removes the lock file. When it
crashes — OOM kill, PHP fatal, server restart — the lock file stays. The
next scheduled run finds the lock taken and either waits until a timeout
or skips the task entirely. This repeats on every subsequent run. From
the admin panel everything looks normal: the task is enabled and appears
in the list. It just never runs.
Identifying the stuck task
The scheduled task log is the first place to check:
Site administration > Server > Tasks > Scheduled task log
Filter by the task name and look for a run that started but has no
matching completion entry, or check the last run time — if it is hours
older than the configured schedule, the task is likely locked.
From the database:
SELECT classname, lastruntime, nextruntime, timestarted
FROM mdl_task_scheduled
WHERE timestarted > 0
ORDER BY timestarted DESC;
For ad-hoc tasks (queued jobs from enrolments, messaging, etc.):
SELECT classname, timestarted, timecreated, faildelay
FROM mdl_task_adhoc
WHERE timestarted > 0
ORDER BY timestarted;
A row with a timestarted value and no corresponding
completion means the task is either still running or was abandoned
mid-run. Cross-check against running PHP processes:
ps aux | grep php
If there is no matching process for the task, the lock is stale.
Finding the lock file
Lock files live in $CFG->dataroot/lock/. The
filenames are derived from the task class name. For example, the lock
for \core\task\send_new_user_passwords_task will be a file
in the lock/ directory with a name based on that class.
ls -la /var/moodledata/lock/
Files older than your expected task duration with no matching running
process are safe to remove.
Clearing a stale lock
For a file-based lock, removing the file is sufficient:
rm /var/moodledata/lock/task_<lockname>
If your installation uses a database lock factory
($CFG->lock_factory = '\core\lock\db_record_lock_factory'),
locks are stored in mdl_lock_db:
SELECT * FROM mdl_lock_db;
DELETE FROM mdl_lock_db WHERE resourcekey LIKE '%classname%';
After clearing the lock, trigger the task manually to confirm it
runs:
Some tasks — H5P content sync, Turnitin submission checks, large
report generation — can run for several minutes and hold a lock for the
entire duration. When they share a cron invocation with fast tasks, a
slow run blocks or delays everything that follows.
Run heavy tasks on their own dedicated CLI invocation, separate from
the general cron:
# In a separate cron entry:
php /var/www/moodle/admin/cli/scheduled_task.php \
--execute='\mod_turnitintooltwo\task\submission_scores_sync'
This keeps the general cron moving and gives you independent control
over the frequency and timeout of the heavy task.
Persistent ad-hoc task
backlogs
Ad-hoc tasks that repeatedly fail accumulate a faildelay
value and are retried with increasing backoff. A large backlog combined
with a lock issue can cause the queue to grow faster than it drains.
Check the queue depth:
SELECT classname, COUNT(*) AS queued, MAX(faildelay) AS max_delay
FROM mdl_task_adhoc
GROUP BY classname
ORDER BY queued DESC;
Tasks with a high faildelay and a large count are
candidates for investigation. If the failure is environmental (a
third-party API that was down, a missing file), clearing
faildelay and resetting timestarted lets them
retry immediately:
UPDATE mdl_task_adhoc
SET faildelay = 0, timestarted = 0
WHERE classname = '\mod_assign\task\cron_task'
AND faildelay > 0;
Only do this once you have resolved the underlying cause.
Moodle cron fails silently more often than you'd expect. This guide explains how to detect those failures reliably using an external heartbeat monitor, and walks through the code that implements it as a Moodle plugin.
Why Moodle’s
built-in cron status is not enough
Moodle shows a “Last cron run” timestamp in Site
administration > Server > Tasks > Scheduled tasks.
That value is written when a cron run starts, not when it
finishes. A run that hits a PHP fatal error, exhausts available
memory, or gets stuck on a locked task still updates the timestamp
before it stops.
The result: the admin panel shows a recent timestamp, everything
looks normal, but no tasks have completed for hours.
The dead man’s switch pattern
An external cron monitor works as a dead man’s switch:
At the end of a successful cron run, your server sends a signal — a
simple HTTP GET request — to a URL that the monitoring service
provides.
The service expects to receive that signal on a schedule you
define.
If the signal does not arrive within the expected window, the
service sends an alert.
The monitoring service has no access to your server. It only waits
for the ping.
Why a scheduled
Moodle task doesn’t work here
The obvious approach would be to add a scheduled task that runs last
and fires the ping. Moodle doesn’t support that. There is no “cron
finished” event, and you cannot configure a task to run after all
others.
More fundamentally: if cron is broken, a scheduled task inside that
cron cannot reliably fire. You need the monitor to live outside of
Moodle’s task scheduler.
The approach: a wrapper
script
The solution is to replace the direct cron invocation with a
pipe:
The 2>&1 merges stderr into stdout so that PHP
errors are captured alongside normal output. The wrapper script receives
everything on stdin, inspects it, and fires the appropriate ping.
The key check
Moodle’s cron script writes one predictable string when it completes
successfully:
Cron script completed correctly
The wrapper reads stdin and looks for that string:
If the string is absent — because cron crashed, was killed, or timed
out — the failure branch runs: it fires the failure ping and emails the
full cron log to the configured recipients.
Sending the ping
The ping itself is a GET request to a configurable URL. Inside a
Moodle CLI script you have the full Moodle stack available, so you can
use Moodle’s own curl class:
require_once($CFG->libdir . '/filelib.php');
$curl = new curl();
$curl->get($url);
Having the URL configurable from within Moodle admin — rather than
hardcoded in a shell script — means an administrator can change the
monitoring endpoint without touching the server.
Storing the URL as a Moodle
setting
A single admin settings page handles all configuration. The success
and failure URLs are stored as plugin config values:
$settings->add(new admin_setting_configtext(
'tool_heartbeat/cron_monitor_success_url',
new lang_string('cron_monitor_success_url', 'tool_heartbeat'),
new lang_string('cron_monitor_success_url_desc', 'tool_heartbeat'),
'',
PARAM_URL
;
You configure a monitor on any dead man’s switch service that accepts
HTTP pings. Set the expected interval to match your cron schedule and
add a grace period long enough to cover normal load variation. When
pings stop arriving, the service sends an alert through whatever channel
you choose — email, SMS, webhook.
Edge cases
OOM kills: If PHP is terminated by the operating
system before producing output, the pipe closes without the success
string. The monitoring service will not receive a ping within the
expected window and will alert. The email log in this case will be empty
or partial — check dmesg for OOM killer entries.
Parallel cron runs: The wrapper applies only to the
CLI invocation managed by the system cron job. If you run multiple
parallel cron processes or use a cron daemon, each invocation needs its
own pipe.
Reading stdin:
file_get_contents('php://stdin') works in most setups, but
on some systems the stream is not immediately available. A fallback
using fopen and fgets is worth adding for
robustness:
We implemented this as a Moodle admin tool plugin
(tool_heartbeat), compatible with Moodle 3.9 and later. It
includes the wrapper CLI script, all admin settings, optional email
notifications with the full cron log on failure, and a master on/off
toggle. Contact Solin if you want to use
it directly.
Monitoring a Moodle web server requires both datacenter-level alerting and application-specific checks. This guide covers configuring your hosting provider's monitoring tools, adding site-specific metrics, and tracking trends over time.
Goal of Monitoring
The goal of monitoring is to ensure that the system, i.e. the web server and all software on it, is working properly and within established parameters. If at any time a website or a subsystem on the web server stops functioning, a signal should be sent out to the sysop, who maintains the system.
In addition, it should also be possible to examine trends over time, or historic data, to evaluate whether or not the system’s resources should be expanded (or scaled back) in the future.
You will notice that we are relying on two monitoring systems now: one provided by the data center, and a monitoring system based on Webmin, which is an administrative system for (web) servers. The reason for adding Webmin’s monitoring is that the data center does not allow you to monitor specific websites, but Webmin does.
1. Check Monitoring Settings of the Data Center
The data center may have its own monitoring that comes pre-installed and configured with a new web server (VPS). Just make sure that everything is set up correctly.
For instance, for HostEurope, do the following. Sign in to HostEurope’s KIS website: https://kis.hosting-provider.de/ and click on the appropriate type of server: either Virtual Server 10+ or Virtual Server. In this guide we show the first type.
In the following screen, click on the login button, under the Contract column:
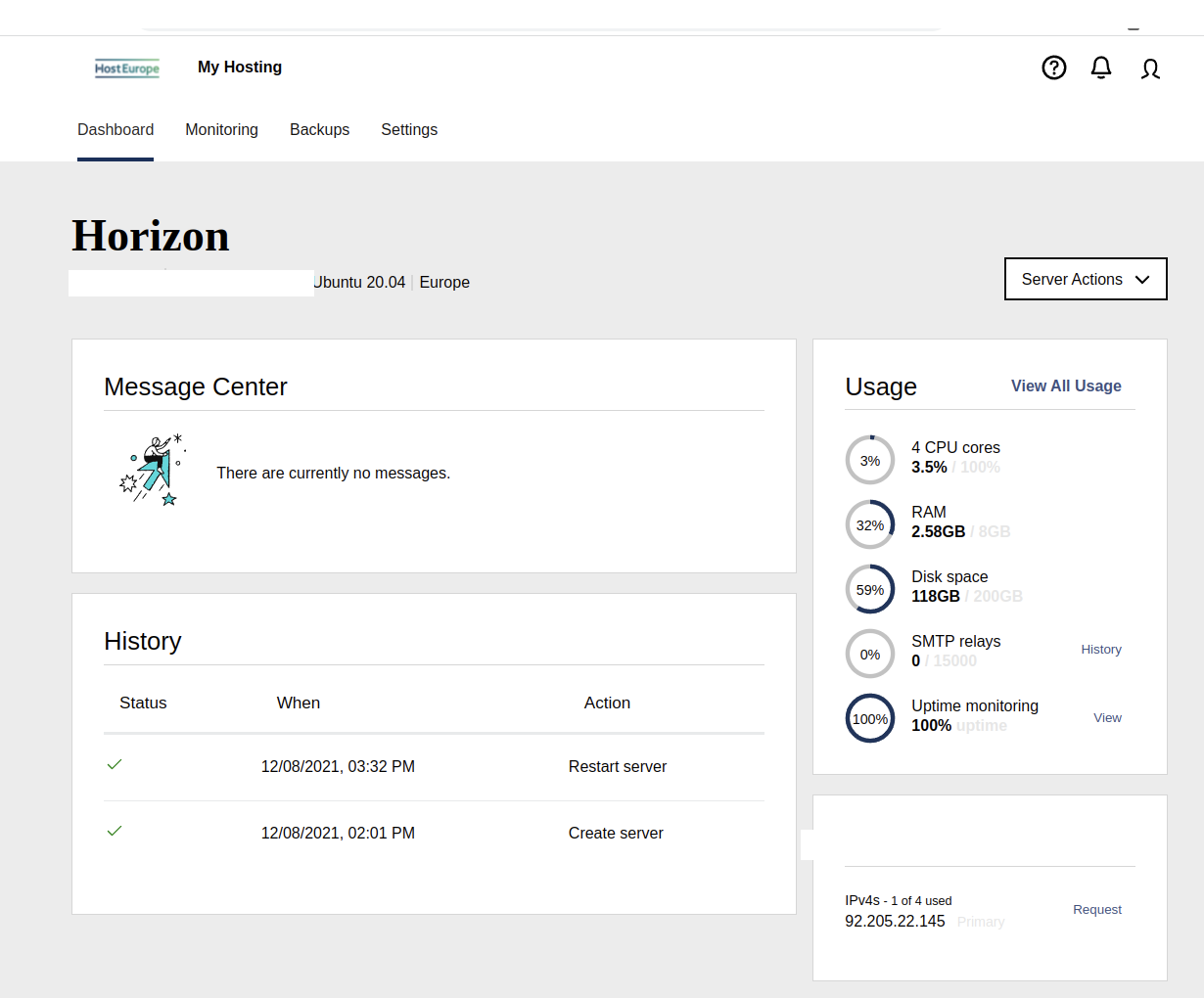
This will open a new browser window (or tab). Here you see the current usage:
The following metrics should not exceed 80%:
CPU cores
RAM
And Disk space should not exceed 95%.
If the system is not used to send out email, then the SMTP relays metric is typically 0.
Ideally, Uptime monitoring is 100%, but may decrease slightly to 99.91% over time.
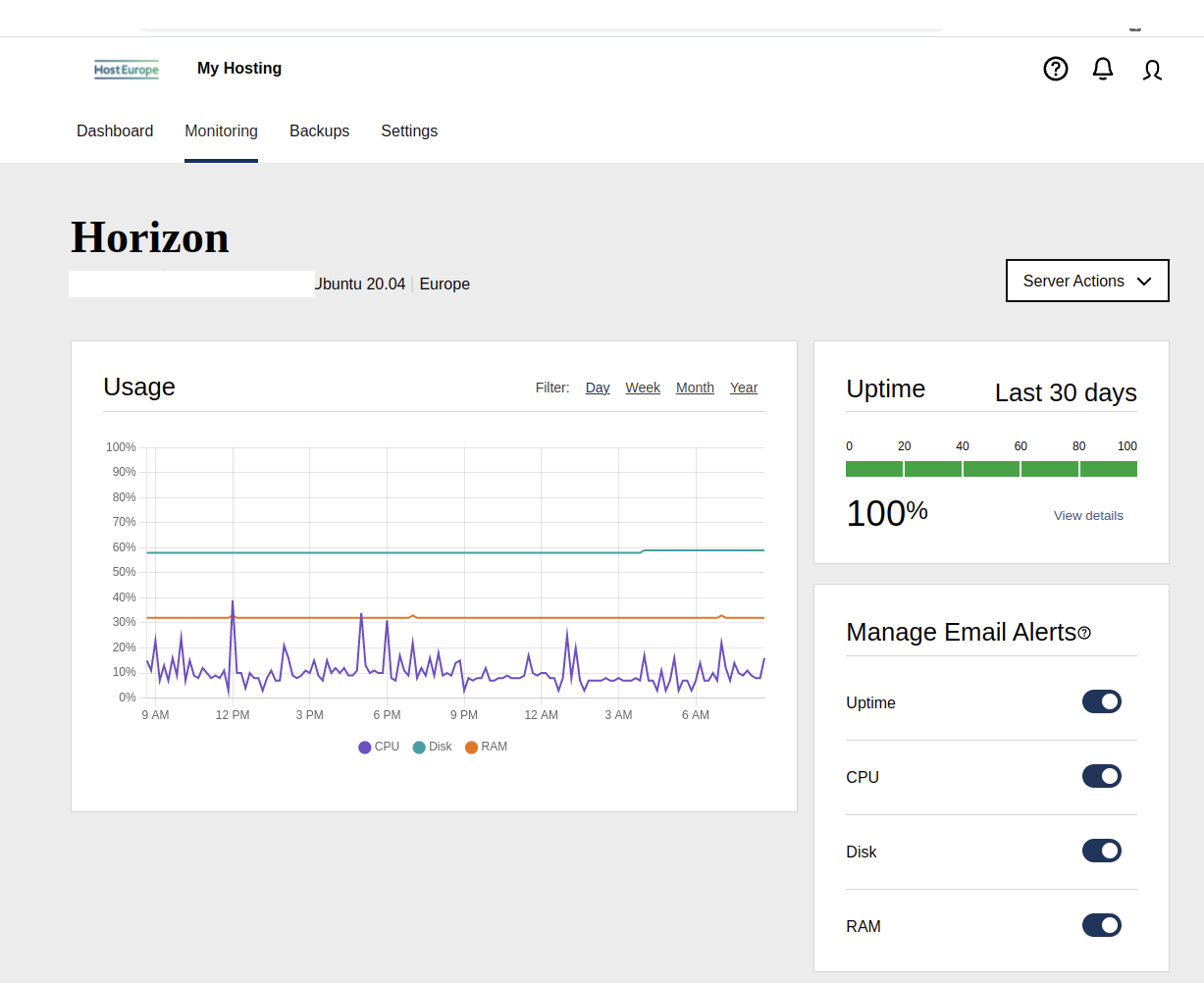
Now click on the Monitoring tab, which should take you to the next screen:
Here, make sure all the settings for Manage Email Alerts are switched on.
This monitor will send out an email to the owner of the KIS account with an alert if either CPU, Disk or RAM usage exceeds 80%.
External Monitoring
It is also recommended to add an external monitor. An external monitor is a monitor that resides on another system. For instance, you can use cronitor.io for free to perform a GET request every five minutes to a website on the server you want to monitor. Don’t forget to add your email address so you will receive notifications when the monitor fails.
Using an external monitor ensures you get alerted if the server goes down even if the entire data center goes down with it.
Heartbeat Monitor
We have a custom plugin, tool_heartbeat, which can be used to send out an “I’m alive” signal to cronitor.io (or a comparable service). Use this tool to make sure Moodle’s (or Totara’s) cron is still working.
Here's how it works:
The Moodle or Totara site stops telling Cronitor "I'm alive!" for whatever reason. (The Heartbeat plugin does this, hence the name.)
Cronitor notices Totara is no longer alive, waits 5 minutes just in case, and then sends out an alert "Type: Alert" ("Event not received on schedule").
If (when) Totara is reanimated, Cronitor sends out an alert "Type: Recovery".
So, in the email messages from Cronitor, "Alert" means there's a problem, and "Recovery" means it's fixed.
Installation and configuration
Place the contents of this directory inside the /admin/tool/heartbeat folder relative to your Moodle or Totara install path.
Configure the cron job to * * * * * php /path_to_your_moodle/admin/cli/cron.php | php /path_to_your_moodle/admin/tool/heartbeat/cli/cron.php > /dev/null
Plugins settings
Cron monitor: Enable the monitor and add the url of the external cron monitor service
Email settings: Enable the email notifications, add the email subject and body, select recipients that get the email.
2. Make sure Webmin is Installed
Our standard procedure is to install Webmin, an administrative system for web servers. So Webmin should be installed and accessible, typically through the hostname and the 10000 port, e.g.: https://vps2.example.internal:10000/.
If it is not installed, please see the installing a new Moodle website.
3. Configure Webmin to Monitor Critical Systems and Websites
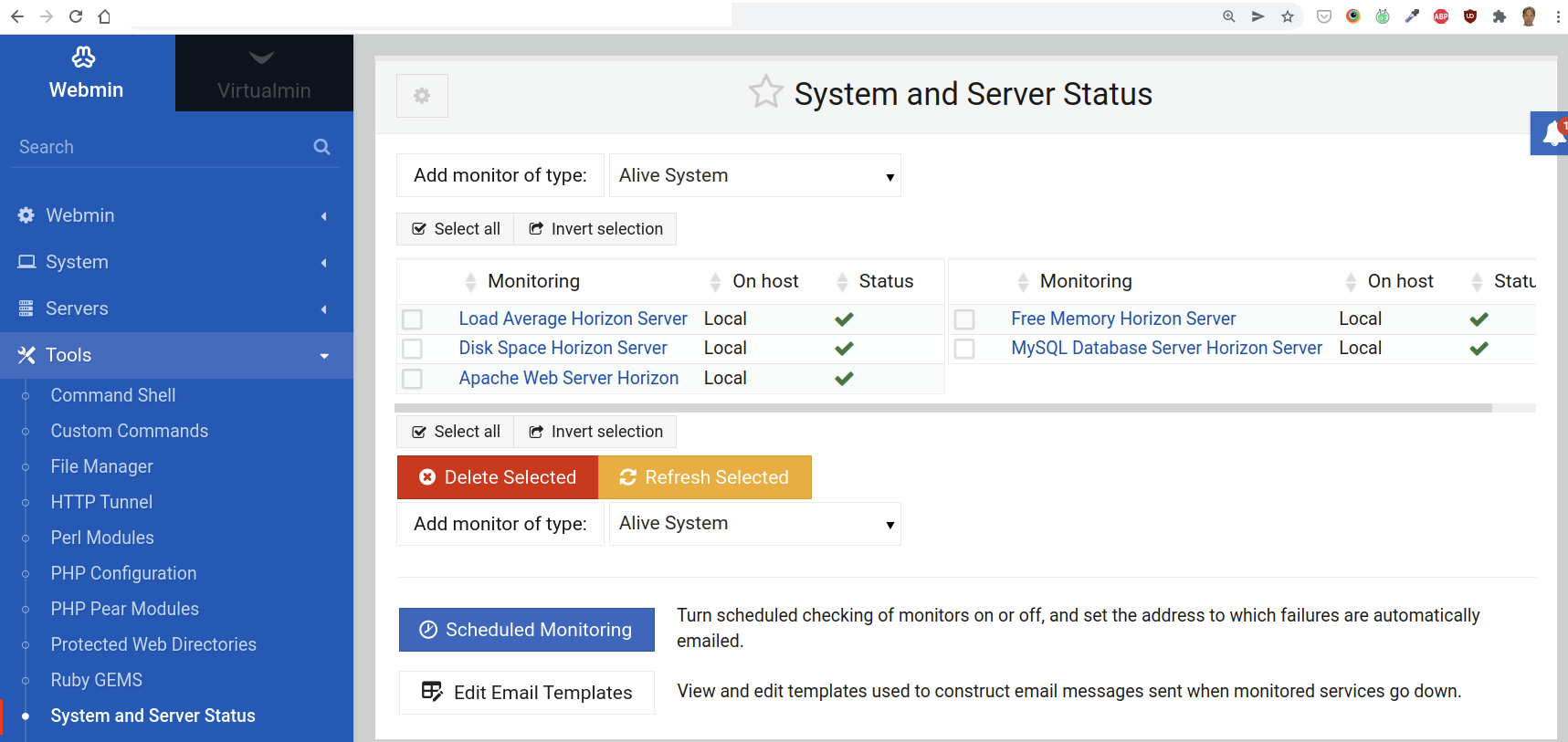
Go to Webmin and open the Tools >System and Server Status section:
We need to add five types of monitors:
Load average: what is the average usage of the system in during the last 15 minutes
Disk space: how much is left on the disk (typically an SSD drive)
Apache web server: is the web server up and running?
Free memory: how much free memory do we have left?
MySQL database server: is the database server up and running?
To add a new monitor in Webmin, use the select box next to the button Add monitor of type and then click the button.
Settings for All New Monitors
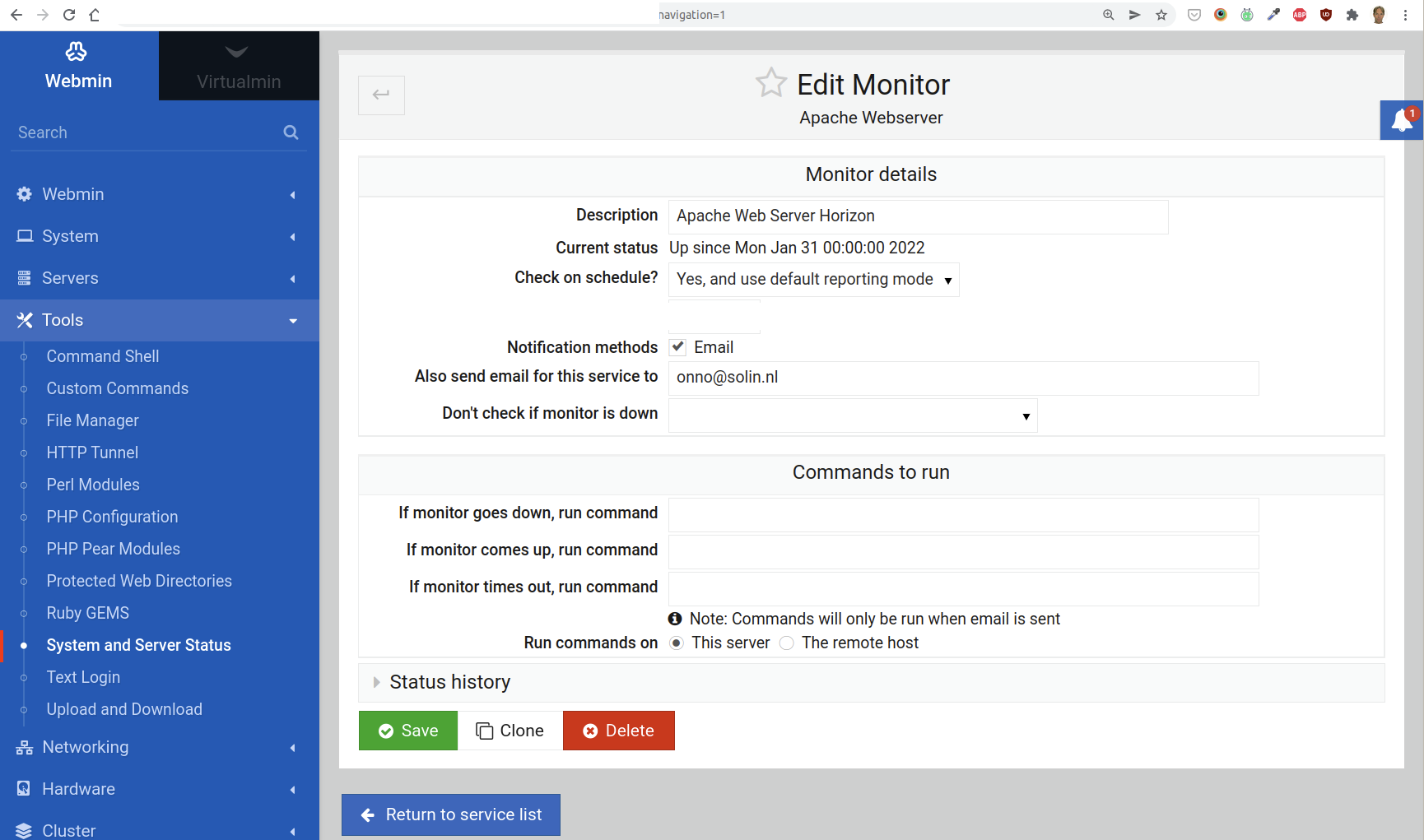
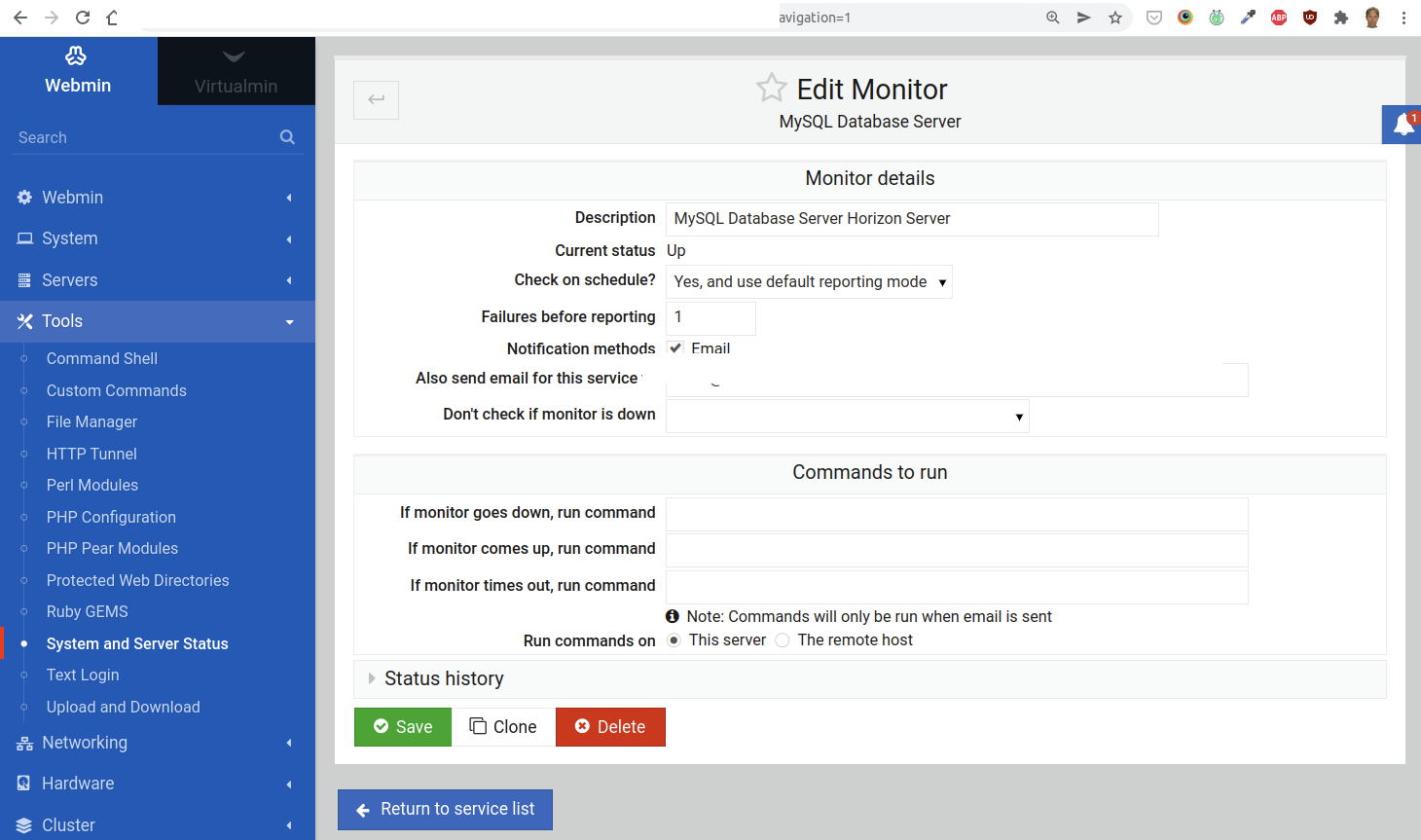
For all new monitors, do not forget to add a Description that includes your users’s name (or main website), and fill out the field “Also send email for this service to” with the address of the person in the sysop role for this server. Set the field “Failures before reporting” to 1. (See the screenshots below for some examples of where to find these fields.)
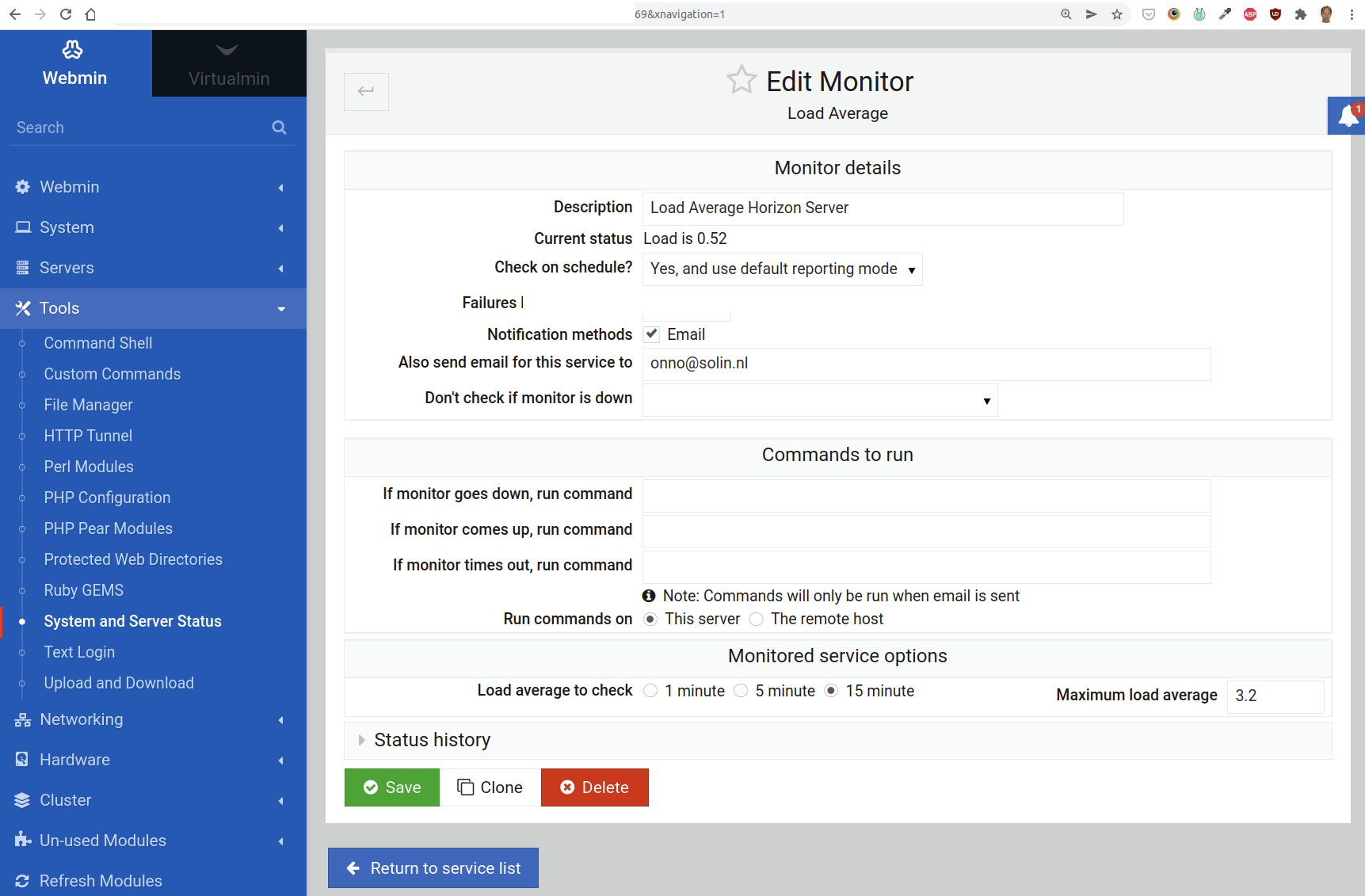
Load Average Monitor
The average load is the usage of the system (mainly CPU usage) during the past 5, 10 and 15 minutes. To get a good perspective, we set this monitor to 15 minutes, under Load average to check.
The Maximum load average value is critical: it should not exceed 80%. The actual value to fill in, is based on the number of CPU cores. This is the computation:
n cores x .8
For instance, 1 core is 0.8, and 4 cores gives you a value of 3.2.
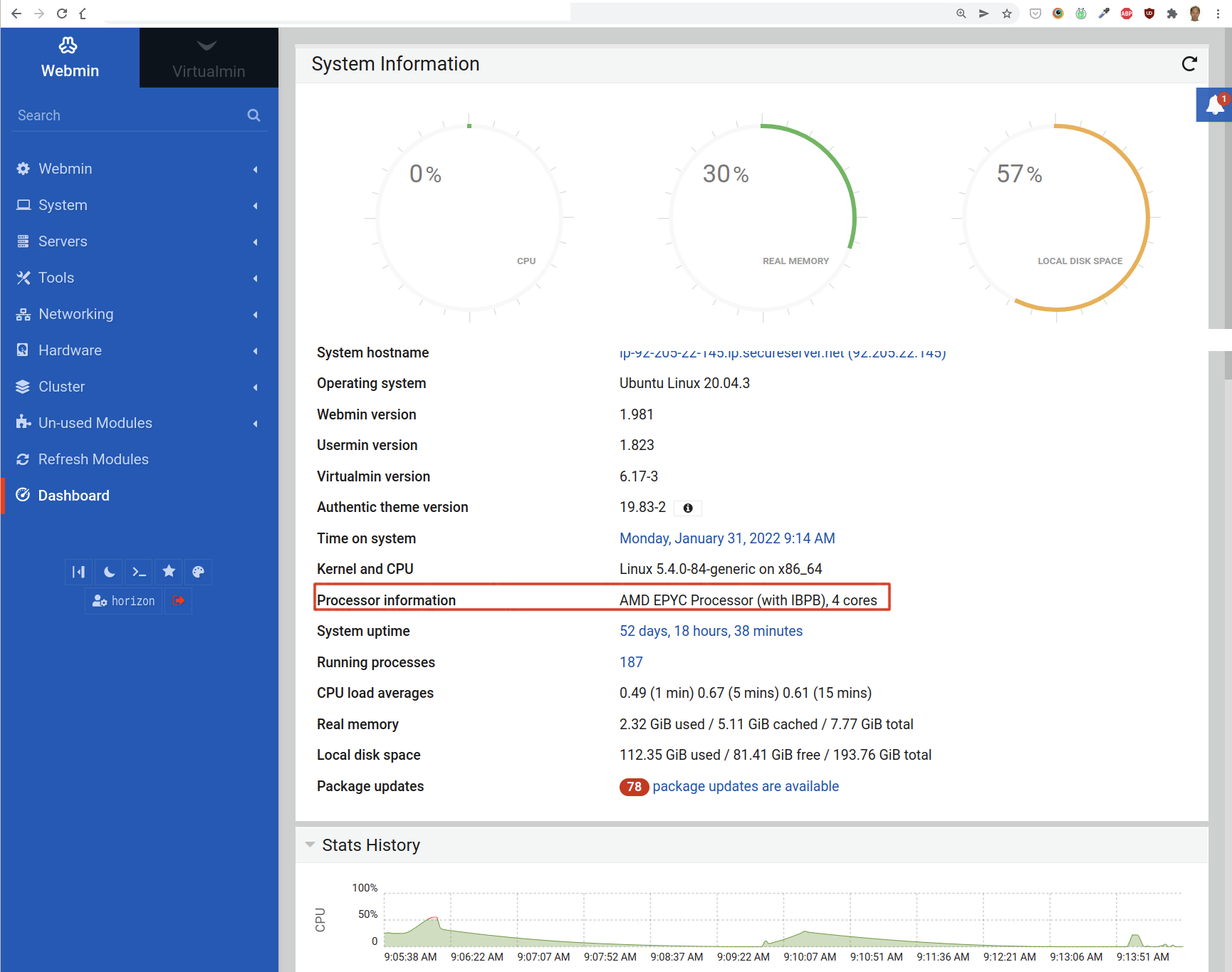
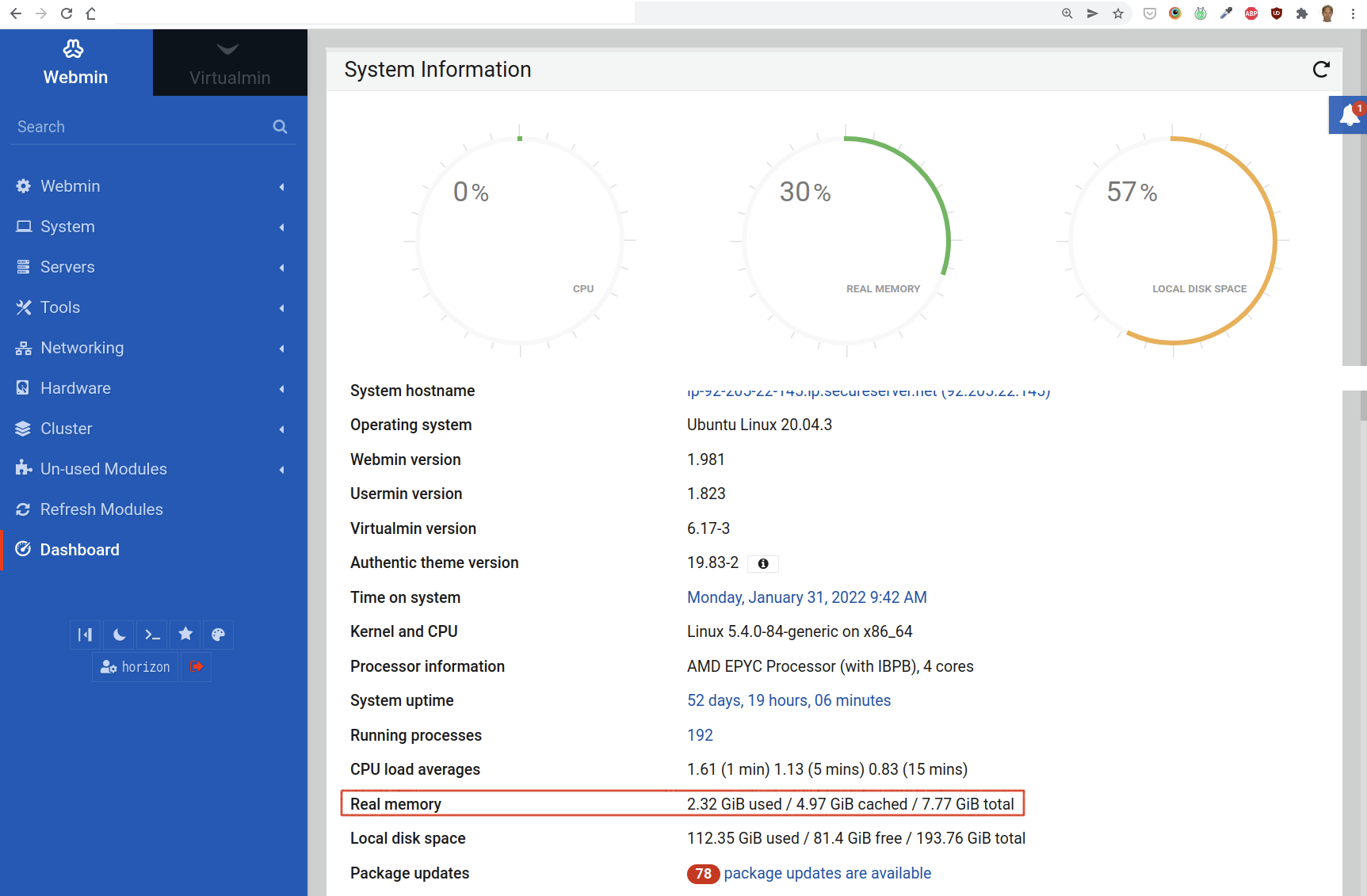
The number of cores can be retrieved from Webmin as well. Simply go to Webmin’s homepage and look for Processor information. There you find the number of cores:
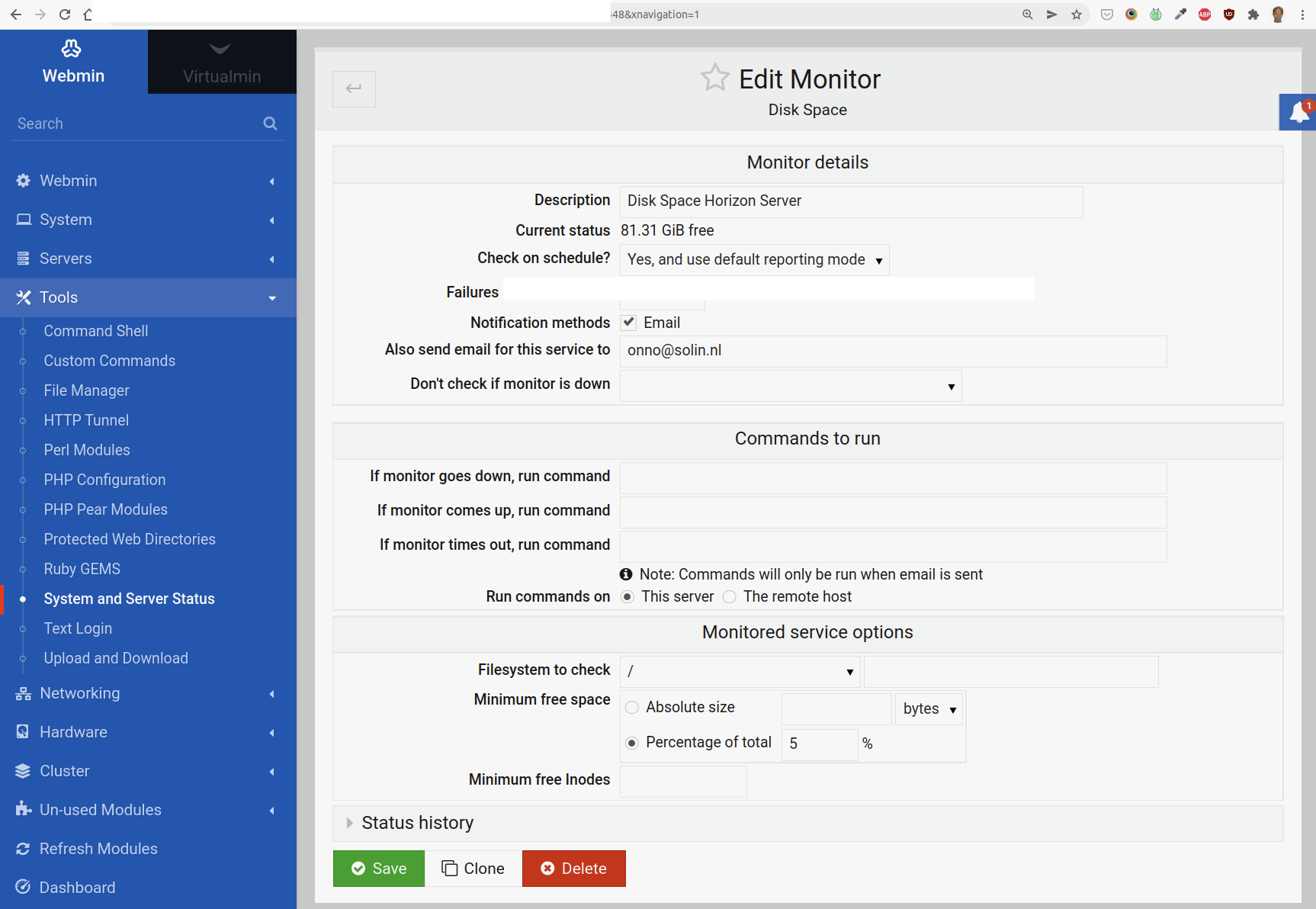
This is pretty straightforward: just fill in 5%. This should send out an alert if the disk is over 95% capacity. Filesystem to check is /.
Apache Web Server Monitor
The defaults for this monitor should be fine.
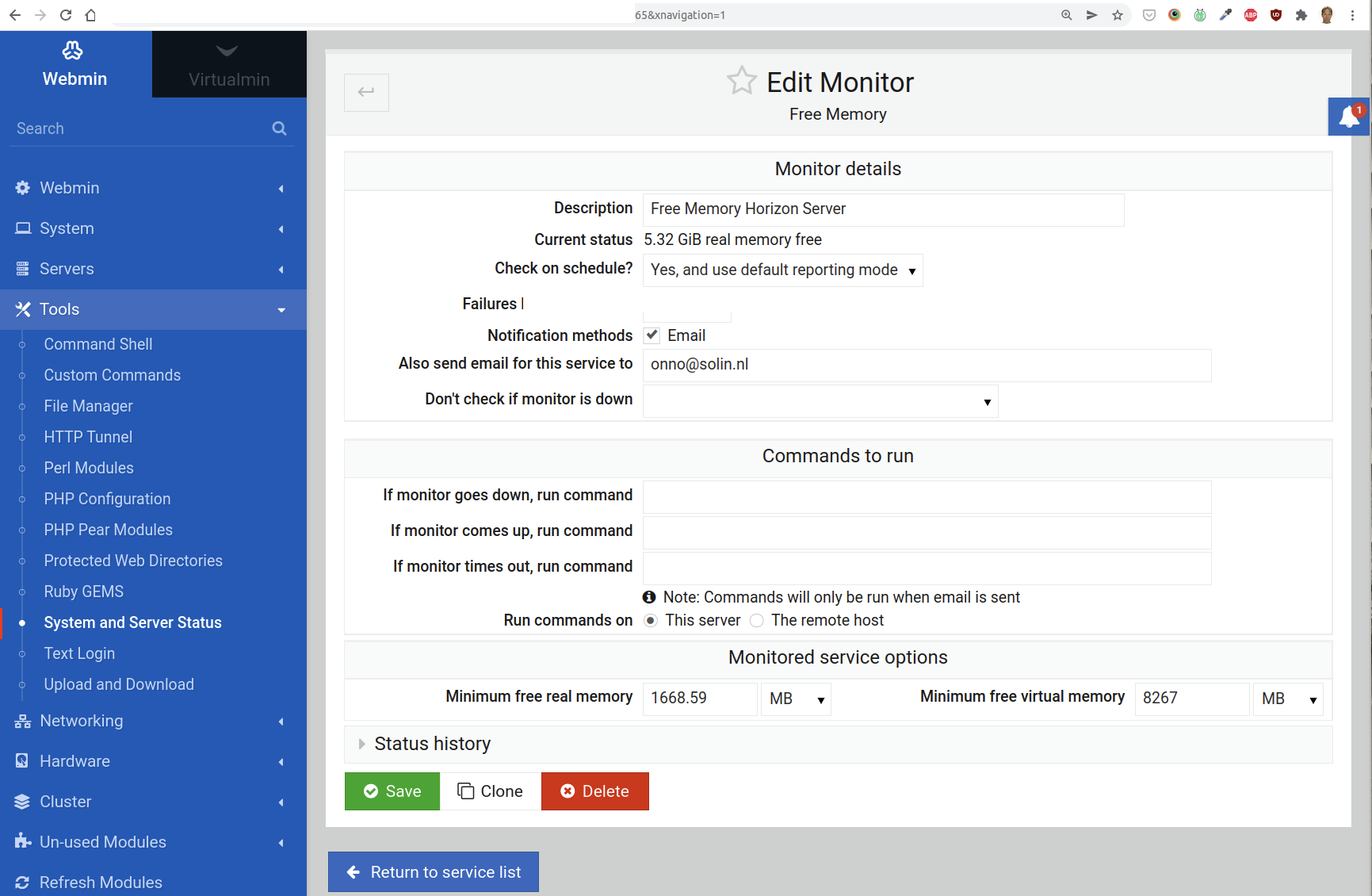
Free Memory Monitor
For this monitor, two values are critical:
Minimum free real memory: we want 20% to be free (or max 80% used)
Minimum free virtual memory: we want this set equal to the amount of physical RAM.
To compute the 20% minimum free RAM, we need to know the total available real memory. You can find this on the “homepage” of Webmin:
Webmin reports the total memory in Gigibytes (GiB). But the Free Memory monitor uses megabytes (MB). To convert the free memory from GiB to MB, use the following formula:
MB = 1073.74 x n GiB
For instance, if we have 7.77 GiB that gives us 8342.9598 MB. Of this number, we take 20% to fill in for the minimum free real memory, and 25% of the virtual memory as the “Minimum free virtual memory”.
MySQL Database Server Monitor
The defaults for this monitor are fine. Make sure that the “Failures before reporting” field is set to 1 and that the “Also send email for this service to” field is filled in.
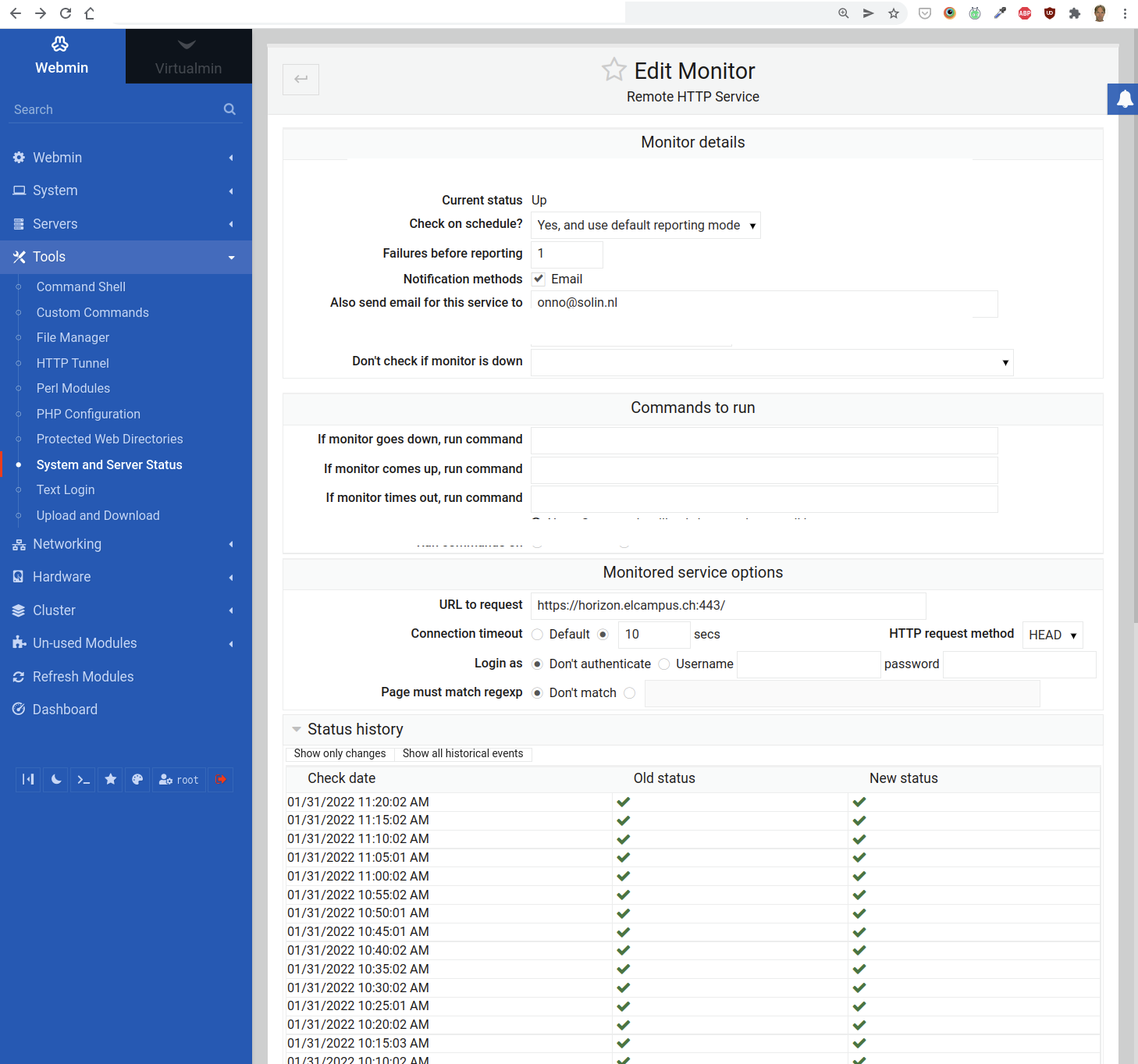
4. Add a “Remote HTTP Service” Monitor to Another Webmin
What happens if the entire web server is out or can no longer be reached? In that case, all the monitors we added in the section above will no longer run, or if they are still running, their email alerts may not reach you.
To counter this, we add a “Remote HTTP Service” monitor to a Webmin installation on another web server entirely:
As you can tell from the Status history, this check is performed every 5 minutes.
Set the field “Connection timeout” to 10 seconds. This should also notify you if the loading times for the Moodle website get unacceptable (i.e. more than 10 seconds).
5. Test the Monitoring
Testing should only be done on a completely new system that is not in use yet. The monitors are typically working – they consist of proven, well tested software. So we will not be testing that the monitoring software works, but mainly that we have configured it correctly.
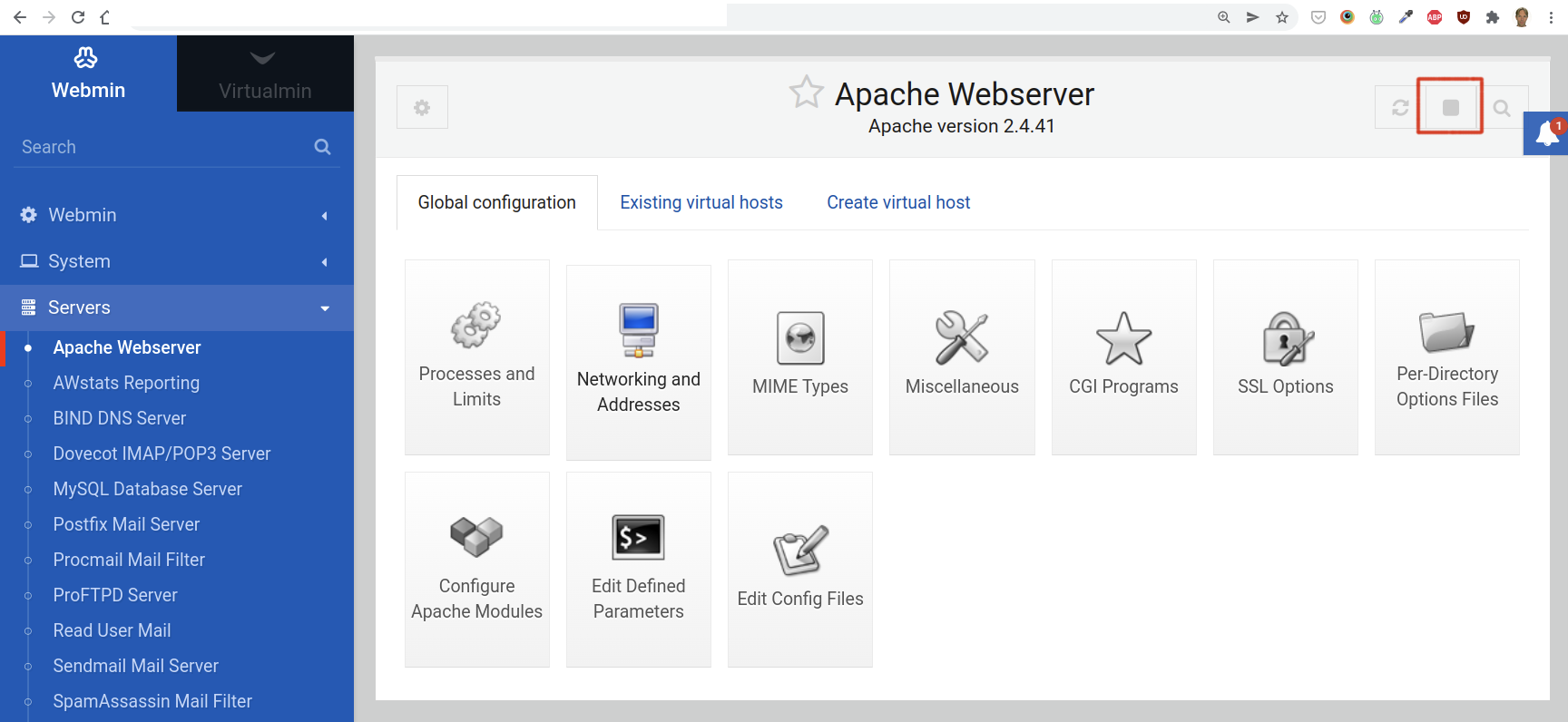
The most critical monitor is the one for the actual Moodle website. We test this by simply turning off the web server. This can be done in Webmin.
Go to Servers > Apache and click the stop button, but only on a new system that is not in use yet:
If you have configured the Remote HTTP Service monitor correctly, you should receive an email very soon.
Restart the Apache web server by clicking on the play button.
You can also stop and start Apache on the command line:
If you do not receive any email, make sure that you have used the correct email address, and the correct url (including the port: nowadays almost always 443).
6. Install a New Munin Node on the Web Server
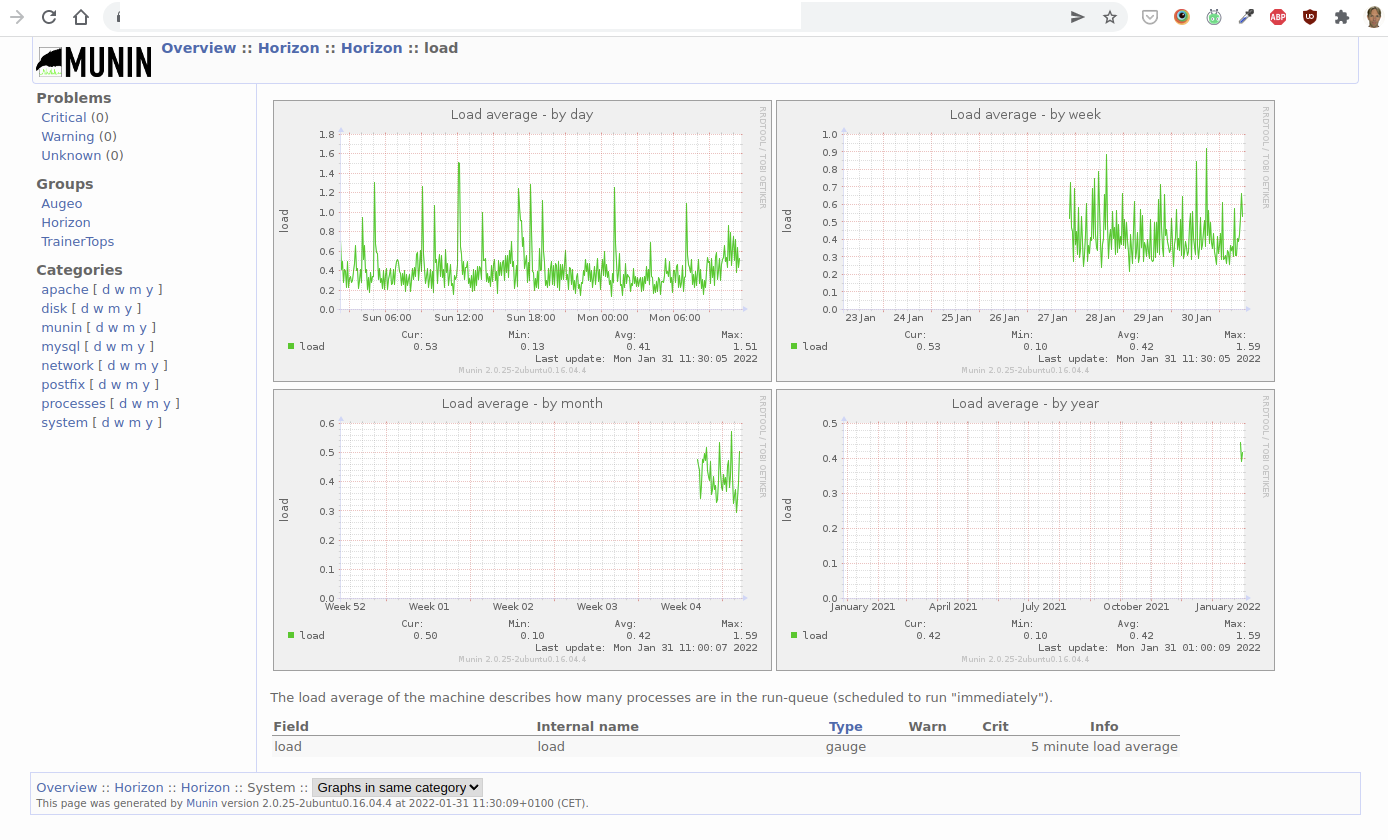
Munin is a logging tool which consists of a server and a node. The node is installed on the system that you want to monitor. The server is where you login to view the historical data. We already have the server in place.
If you login to monitoring.example.internal, you will see an overview of the systems that we are currently monitoring through Munin. Click on a specific system to view the details. Here is an example of the history of the load average:
To install the node on a new web server:
Make sure that the library libparse-http-useragent-perl is installed, e.g.:
sudo apt-get install libparse-http-useragent-perl
Install munin:
apt-get install munin
apt-get install munin-node
Make sure that the Apache’s server-status module is enabled. (You can do this through Webmin.)
Add the ip address of the Munin server (i.e. the “master”) to /etc/munin/munin-node.conf:
allow ^xxx\.xxx\.xxx\.xxx$
Configure the munin plugins.
Configuring The Munin Plugins
The default plugins for the node (so, on your Munin “client” web server) are in /usr/share/munin/plugins/. They appear in your munin website if they're symlinked in /etc/munin/plugins. For instance:
In /etc/munin/plugins, add symlinks to the apache plugins:
You must also configure them in the file /etc/munin/plugin-conf.d/munin-node. In that file, if you want to configure multiple plugins at once, use an asterisk notation. E.g.:
[apache*]
This addresses all apache plugins, which are by default:
apache_accesses
apache_processes
apache_volume
Usually when you look at the source code of the plugins (they're mostly perl scripts), you will find configuration instructions. For instance, the apache plugins need access to Apache's server status, so you have to configure Apache (i.e. httpd.conf):
<Location /server-status>
SetHandler server-status
Order deny,allow
Deny from all
Allow from 127.0.0.1
</Location>
ExtendedStatus on
We should also mention here that some plugins seem to exclude each other. For instance, the apache_average_time_last_n_requests plugin (not installed by default) seems to exclude the other (default) apache plugins.
Finally, restart the node:
/etc/init.d/munin-node restart
And open the firewall for port 4949.
Please note: if any of the Munin plugins fail, you will not see any date from that Munin node on the server (monitoring.example.internal)!
Configure The Munin Server
Finally, you also have to tell the Munin server to start polling the newly added node. Add the ip address of the node server to the file /etc/munin/munin.conf:
[ArbitraryServerName] # Apparently, you can't use spaces in this name
address xxx.xxx.xxx.xxx
use_node_name yes
The Munin server (the 'master') will read the new values within 5 minutes (the default polling interval).
Detailed Monitoring
If you run into any trouble with a VPS, you can add more detailed monitoring.
Performance Monitoring
The following is a monitoring script based on an email exchange with Hosting Provider, May 19th 2022 about the website outages on their VS10 Linux VPS (search for 198.51.100.43 #HE-DE:2ad1f7b4109530473 in the email history).
date >> /var/log/custom-monitoring.log; top -n 1 -b >> /var/log/custom-monitoring.log; lsof -ni >> /var/log/custom-monitoring.log
This log will contain detailed performance information which you can use to identify which particular application is causing high load, for instance.
Explanation:
date: current date and time
top: display linux processes;
-n 1: Specifies the maximum number of iterations, or frames, top should produce before ending.
-b: Starts top in Batch mode, which could be useful for sending output from top to other programs or to a file. In this mode, top will not accept input and runs until the iterations limit you've set with the `-n' command-line option or until killed.
lsof: lists on its standard output file information about files opened by processes
-i: selects the listing of files any of whose Internet address matches the address specified in i. If no address is specified, this option selects the listing of all Internet and x.25 (HP-UX) network files.
-n: selects the listing of files any of whose Internet address matches the address specified in i. If no address is specified, this option selects the listing of all Internet and x.25 (HP-UX) network files.
Log File Rotation
This type of monitoring generates a lot of data, so put it in log file rotation, see Webmin > System > Log File Rotation (the one for /var/log/letsencrypt/*.log is a good example).
Use the default settings, except for:
Rotation schedule: Daily
Number of old logs to keep: 31, so you will always have at least a month's worth of data.
Compress old log files?: Yes.
Slow Query Monitoring for MySQL
MySQL has a slow query log which records all queries which took longer than 10 seconds (by default) to execute. For Moodle, 10 seconds is not realistic because many queries take longer than that, so 30 seconds is probably better.
To activate slow query logging:
Login using the mysql client: sudo mysql -uroot -p
set global slow_query_log = 'ON';
set global slow_query_log_file ='/var/log/mysql/slow-query.log';
set global long_query_time = 30;
Confirm the changes are active by re-entering the MySQL shell (this reloads the system variables) and running the following command: show variables like '%slow%';
Make sure the slow-query.log is in log rotation (see subsection Log File Rotation).
Incident Response
If you receive an alert from either monitoring system, take the following steps:
Verify the alert
If normal usage was impeded, i.e. there was an actual outage, notify your users, with an estimated time to fix if possible
Fix the issue
Take steps to prevent this from happening again (and document them in a relevant SOP)
If there was an outage, notify your users that the issue is now fixed and what you have done, or will do in the very short term, to prevent a recurrence of the incident.
Appendix – Health Monitoring on Servers Without Webmin
Purpose
This section describes how basic server health monitoring is implemented on systems where Webmin is not installed or not permitted.
Instead of relying on a web-based administration interface, monitoring is achieved using:
a lightweight Bash script
systemd timers
standard Unix tooling (mail, logrotate)
This approach minimizes attack surface, avoids additional services, and is fully auditable.
Rationale (Why No Webmin)
Webmin provides convenient monitoring and administration features but:
introduces an additional web-facing service
increases maintenance and patching requirements
is not always allowed under security policies
For these reasons, this server uses a script-based monitoring approach that:
requires no open ports
has no daemon processes
depends only on standard OS components
provides clear alerting and diagnostics
Monitoring Scope
The health check verifies the following:
Disk usage on the root filesystem (/)
System load (1-minute average, normalized per CPU core)
Available memory (MemAvailable)
Required services:
apache2
postgresql
Local HTTP availability via http://127.0.0.1/
On failure:
a diagnostics snapshot is appended to a log file
an alert email is sent
On success:
a single “OK” line is written to the log
no email is sent
Installation
Prerequisites
Ensure mail utilities are installed:
apt update
apt install mailutils
Postfix is already present on this system.
Script Installation
Create the monitoring script:
vim /usr/local/sbin/healthcheck.sh
Insert the full script source provided below.
Set permissions:
chmod 0755 /usr/local/sbin/healthcheck.sh
Create the state directory:
mkdir -p /var/lib/healthcheck
systemd Configuration
Create the service unit:
vim /etc/systemd/system/healthcheck.service
[Unit]
Description=Basic server health check
[Service]
Type=oneshot
ExecStart=/usr/local/sbin/healthcheck.sh
Create the timer unit:
vim /etc/systemd/system/healthcheck.timer
[Unit]
Description=Run healthcheck every 5 minutes
[Timer]
OnBootSec=2min
OnUnitActiveSec=5min
AccuracySec=30s
[Install]
WantedBy=timers.target
To prevent alert emails from being classified as spam or overlooked:
Create a mail filter or rule in the mail client:
Match subject containing:[ALERT][Totara][ubuntu]
Always deliver to inbox (or mark as important)
Optionally apply a label such as “Server Monitoring”
This ensures alerts remain visible while avoiding unnecessary inbox noise.
Script Source Code
/usr/local/sbin/healthcheck.sh
#!/usr/bin/env bash
set -euo pipefail
HOSTNAME_SHORT="$(hostname -s)"
HOSTNAME_FQDN="$(hostname -f 2>/dev/null || hostname)"
NOW="$(date -Is)"
# -----------------------------
# CONFIG (defaults, overridable via environment)
# -----------------------------
: "${ALERT_EMAIL:=onno@solin.co Lee@teaching4business.com nikki@teaching4business.com}"
: "${MAIL_FROM:=monitoring@solin.co}"
: "${DISK_MAX_PCT:=95}"
: "${LOAD_PER_CORE_MAX:=1.50}"
: "${MEM_AVAIL_MIN_MB:=512}"
: "${HTTP_URL:=http://127.0.0.1/}"
: "${ALERT_COOLDOWN_SECONDS:=1800}"
: "${STATE_DIR:=/var/lib/healthcheck}"
SERVICES=("apache2" "postgresql")
# -----------------------------
log_line() {
echo "[$NOW] $*" >> /var/log/healthcheck.log
}
send_alert() {
local subject="$1"
local body="$2"
printf "%s\n" "$body" | mail -a "From: ${MAIL_FROM}" -s "$subject" ${ALERT_EMAIL} || true
}
rate_limited() {
local key="$1"
local stamp="${STATE_DIR}/${key}.stamp"
local now
now="$(date +%s)"
mkdir -p "$STATE_DIR"
if [[ -f "$stamp" ]]; then
local last
last="$(cat "$stamp" || echo 0)"
now - last < ALERT_COOLDOWN_SECONDS && return 0
fi
echo "$now" > "$stamp"
return 1
}
fail() {
local key="$1"
local msg="$2"
log_line "FAIL ${HOSTNAME_SHORT}: ${msg}"
{
echo "----- failure snapshot ($NOW) -----"
uptime
echo
df -h
echo
free -m
echo
top -b -n1 | head -n 60
echo
ss -tulpn
echo
systemctl --failed
echo "----------------------------------"
} >> /var/log/healthcheck.log
rate_limited "$key" && exit 1
send_alert "[ALERT][Totara][${HOSTNAME_SHORT}] healthcheck failed: ${key}" \
"Time: $NOW
Host: ${HOSTNAME_FQDN}
Reason:
${msg}
See /var/log/healthcheck.log for diagnostics."
exit 1
}
touch /var/log/healthcheck.log
disk_pct="$(df -P / | awk 'NR==2{gsub("%","",$5); print $5}')"
[[ "$disk_pct" -lt "$DISK_MAX_PCT" ]] || fail disk "Disk usage ${disk_pct}%"
cores="$(nproc)"
load_1m="$(awk '{print $1}' /proc/loadavg)"
awk -v l="$load_1m" -v c="$cores" -v t="$LOAD_PER_CORE_MAX" 'BEGIN{ exit !l/c)<=t) }' \
|| fail load "Load ${load_1m} on ${cores} cores"
mem_avail_mb="$(awk '/MemAvailable/ {print int($2/1024)}' /proc/meminfo)"
[[ "$mem_avail_mb" -ge "$MEM_AVAIL_MIN_MB" ]] \
|| fail memory "MemAvailable ${mem_avail_mb}MB"
for svc in "${SERVICES[@]}"; do
systemctl is-active --quiet "$svc" \
|| fail "service-${svc}" "Service not active: ${svc}"
done
curl -fsS --max-time 10 "$HTTP_URL" >/dev/null \
|| fail http "Local HTTP check failed"
log_line "OK ${HOSTNAME_SHORT}"
exit 0
Diagnosing Moodle problems systematically requires checking error logs, database integrity, cron execution, and plugin conflicts. This guide walks through the troubleshooting workflow and specific checks for common failure modes.
List the Symptoms
Get access to Moodle and server
Ask your users for:
Moodle url
Moodle admin username
Moodle admin password
Web server url or ip address
Web server username
Web server password
If the Moodle website is hosted on one of our own servers, we should already have this information – don’t bother your users in that case, but ask the lead engineer instead.
Find the Root Cause
Checking and Enabling X-Sendfile for Large File Delivery (Moodle)
Overview
When Moodle serves large files (video, H5P assets, SCORM, large images), the default behaviour is for PHP-FPM to stream the file through pluginfile.php. This can block PHP workers for minutes and cause sitewide slowdown. Apache’s mod_xsendfile allows Apache to serve files directly from moodledata, bypassing PHP entirely. This section describes how to enable X-Sendfile and how to test whether it is working.
Symptoms
Slow or hanging requests to pluginfile.php.
PHP-FPM slow logs show stack traces in byteserving_send_file() or readfile_accel().
Many long-running PHP-FPM workers during video playback.
Users report Moodle becoming unresponsive while accessing large videos or files.
Step 1: Verify Apache has mod_xsendfile
On the server, run:
a2enmod xsendfile
If the module is missing, install it:
apt update
apt install libapache2-mod-xsendfile
a2enmod xsendfile
service apache2 restart
Step 2: Add required directives to the vhost
Inside the VirtualHost:
<IfModule mod_xsendfile.c>
XSendFile on
XSendFilePath /path/to/moodledata
XSendFilePath /path/to/moodle/code
</IfModule>
Php-fpm may cause trouble if the number of pm.max_children is set too low, for a specific vhost (this is configured through a ‘pool’ file). You’ll see this mentioned in the log, /var/log/php7.4-fpm.log, e.g.:
[30-Sep-2021 10:08:11] WARNING: [pool www] server reached pm.max_children setting (5), consider raising it
Or:
26-Oct-2023 11:50:13] WARNING: [pool 1692438784256193] server reached pm.max_children setting (16), consider raising it
On Ubuntu (HostEurope), the config file for the web user (typically www-data) is here:
/etc/php/X.Y/fpm/pool.d/www.conf. The other pool files are in the same directory. For instance:
Here, 1692438784256193.conf is the php8.1-fpm configuration file for the user elo. How do we know? Well, virtualmin creates an entry in the vhost conf file, e.g. /etc/apache2/sites-available/portal.blueyonder-coaching.example.conf:
As you can see, the socket number matches with the number used in the conf file name.
In addition, we find the user elo in the output of the php8.1-fpm configuration command:
php-fpm8.1 -tt
Which yields (for this example):
[1692438784256193]
prefix = undefined
user = elo
group = elo
listen = /var/php-fpm/1692438784256193.sock
Again, the numbers match and here the socket is also explicitly mentioned.
So, in the php-fpm conf file that you have found, change the setting for pm.max_children, e.g. from 5 to 25 (this is really just an example, see the spreadsheet below to compute the actual value), and do:
command outputs free and available memory. Use the available memory in your calculations.
The difference between free memory vs. available memory in Linux is, free memory is not in use and sits there doing nothing. While available memory is used memory that includes but is not limited to caches and buffers, that can be freed without the performance penalty of using swap space.
Use something like pstree -c -H 19741 -S 19741 to see the current number of php-fpm7.4 processes, where you find the pid by looking for php-fpm: master process (/etc/php/7.4/fpm/php-fpm.conf) in the output of ps -ef. This tells you how many ‘children’ are currently spun up.
Compute php-fpm process size:
python /usr/local/bin/ps_mem.py | grep php-fpm (grab the Python script here).
A final thing to keep in mind is ‘if these "tuned" values are calculated based on the maximum capacity of yyour server and you put the same values to every site, you'll consume your resources multiple times. Instead, these values should be distributed between the pools so that the sum from all pools is equivalent with the "tuned" value.’
(..) ‘Whatever you do, keep your sites in separate pools with separate user accounts. Otherwise a compromise on a single site can spread across all your sites.’
The latest versions of Virtualmin (writing this 20231026) seem to automatically create a pool file for each new vhost. These articles describes how to do it manually:
From the latter article: “To complete the process, you should repeat the steps for each of your virtual hosts. When you are entirely sure mod_php is not being used anymore you can disable it through
$ sudo a2dismod php8.1
Until you've done this, Apache will still include a PHP process for every request, meaning the memory usage will stay the same and possibly be even higher.”
Checking php-fpm Configuration
Simply use this command to see the configuration parameters that are currently being used:
php-fpm8.1 -tt
And use the following command to test whether the configuration is correct:
php-fpm8.1 -t (or php-fpm8.1 --test)
As an aside, you can also check the configuration for Apache:
apachectl configtest
Checking the php-fpm status
Go to /etc/php/X.Y/fpm/pool.d/www.conf (e.g. /etc/php/7.4/fpm/pool.d/www.conf) and look for pm.status_path. Uncomment it and add /phpXY-fpm/status, e.g.:
pm.status_path = /php74-fpm/status
(Do NOT insert a dot here)
Then, in your /etc/apache2/apache2.conf file, add:
Obviously, the paths must match exactly. Restart Apache and php-fpm, and go to your web server’s location, e.g.:
http://213.165.72.180/php81-fpm/status
This should give you something like:
pool: www
process manager: dynamic
start time: 26/Oct/2023:13:37:45 +0000
start since: 13
accepted conn: 1
listen queue: 0
max listen queue: 0
listen queue len: 0
idle processes: 31
active processes: 1
total processes: 32
max active processes: 1
max children reached: 0
slow requests: 0
Please note: this only shows the status for that specific pool. In the example above, that’s www.
Sluggish Moodle Or Totara Site
Check the images that themes like Adaptle allow you to upload for the frontpage, header and background. We once had a Moodle site that was loading two essentially the same images of 7 MB each. Needless to say, this makes loading the site quite sluggish.
The scheduled tasks may add up, especially if you have many users and many automatic cohort syncs (audiences, in Totara). Please note that Totara (and Moodle prior to version 3.7) does not have the task_scheduled table. No serious logging takes place for scheduled tasks.
MySQL Connection Timeout Or Lost Connection
From your-vps server, /etc/mysql/mysql.conf.d/mysqld.cnf:
## TEMP 20230322 the lead engineer - successfully imported a 2.8 GB dump with these settings - main thing is innodb_buffer_pool_size which must be SMALLER
## See https://dba.stackexchange.com/questions/124964/error-2013-hy000-lost-connection-to-mysql-server-during-query-while-load-of-my
#innodb_lock_wait_timeout = 60
#net_read_timeout = 28800
#net_write_timeout = 28800
#connect_timeout = 28800
#wait_timeout = 28800
#delayed_insert_timeout = 28800
#innodb_buffer_pool_size = 4294967296
Timeout Issues
mod_fcgid: read data timeout in 40 seconds
This error may pop up if you’re using fcgi and you’re trying to upload a large scorm file (say 400M) that requires quite some processing time:
mod_fcgid: read data timeout in 40 seconds
(This error may be disguised as a HTTP 500 error, but the Apache log file should contain the actual error message.)
The solution is to increase the value of FcgidIOTimeout in your vhost configuration, e.g.:
FcgidIOTimeout 600
This directive can be put directly inside the VirtualHost part of the Apache configuration file for the website, e.g.:
<VirtualHost 11.22.33.44:443>
FcgidIOTimeout 600
Don’t forget to save the conf file and restart the webserver afterwards, with /etc/init.d/apache2 graceful.
Varnish Timeout
Usually it’s enough to increase max_execution_time in php.ini to solve any timeout issues. However, I recently (20250206) encountered a timeout issue in an AWS EC2 instance that turned out to be using Varnish, which is a caching tool.Varnish was set (in /etc/varnish/.default.vcl) to 30s. After resetting set bereq.first_byte_timeout to 300s (notice the ‘s’ by the way: Varnish completely crashes the site if you leave it out), I had to restart varnish:sudo systemctl restart varnish
And that solved the issue (together with the max_execution_time increase, of course).
Common But Hard to Spot Issues
Spaces in PHP Files
If you inadvertently introduce a space before the <?php opening tag, especially in config.php, things will go wrong. This will pollute the output buffer in cases where output is created and sent to the browser through php, e.g. pluginfile.php or theme/yui_combo.php. Examples are images, css, and javascript. If any output, such as a space, is sent before the headers, the results are catastrophic, especially for all binary files such as files (often, css and javascript is zipped before being sent to the browser, making these resources binary too).
Symptoms: images do not load, no layout (css) is applied and menus (requiring javascript) do not work.
Configuration Issues
Unexpected Name Showing as Sender in Course Welcome Emails
We encountered a case where Moodle’s course welcome emails were being sent with the name of an unrelated user as the sender. This was confusing, since the person whose name appeared had nothing to do with the specific course.
Root cause By default, the setting Send course welcome message – From in the Manual enrolments plugin (/admin/settings.php?section=enrolsettingsmanual) was configured as From the course contact. Moodle interprets “course contact” as the first user it finds with a role listed in the coursecontact configuration (commonly the editingteacher role). Importantly, this lookup also includes role assignments at the system or category level, not only at the course level. Because a user had the editingteacher role at system level, their name was used as the sender in welcome emails across the site.
Resolution We changed the configuration in: Site administration Plugins Enrolments Manual enrolments
Setting: Send course welcome message – FromFrom the no-reply address
This ensures that all course welcome emails are now sent from the neutral noreply address (e.g. noreply@example.com), and no personal user names appear unexpectedly as the sender.
Best practice Always configure Send course welcome message – From to From the no-reply address unless there is a strong reason to display the course contact’s name. This avoids confusion and ensures consistency across all courses.
Case Study: Extremely Slow Course Creation (ICM 2025)
Symptoms
Creating a new course in Moodle 4.1 took minutes to complete, whereas on the previous host it completed in under 30 seconds. Logging in via SAML2 also appeared slower.
Root Cause
The issue was caused by inefficient MySQL write performance, specifically InnoDB’s default behavior of flushing transaction logs to disk after every single write operation. This configuration is safe but can be extremely slow on systems handling many small transactions (like Moodle’s course creation process).
In this case, the new hosting environment used SSD storage but was still using conservative, HDD-era MySQL defaults:
innodb_flush_log_at_trx_commit = 1
innodb_io_capacity = 200
innodb_io_capacity_max = 2000
This caused excessive fsync operations (waiting for every commit to fully write to disk).
Resolution
The hosting partner (Kaliber) optimized MySQL for modern SSD storage and Moodle’s workload. The following key changes were applied:
Increasing innodb_io_capacity allows MySQL to perform more I/O operations per second, aligning with SSD capabilities.
Setting innodb_flush_log_at_trx_commit = 2 reduces log flushes to once per second instead of every transaction — a safe compromise that greatly reduces latency.
Increasing I/O threads improves concurrency on SSDs with multiple queues.
Testing on the development server confirmed that even the most aggressive options (O_DIRECT_NO_FSYNC) only gave minimal additional gain; the 1 fsync per second configuration was the “golden mean.”
After implementing these settings, the “Create new course” operation returned to expected performance levels (seconds rather than minutes).
Lessons Learned / Best Practice
Moodle’s “create course” is a write-heavy operation; database write latency dominates performance.
Always review and tune MySQL’s InnoDB write path after migrations.
On SSDs, conservative defaults such as innodb_flush_log_at_trx_commit=1 and low I/O capacity settings can cause severe slowdowns.
This issue occurred on the ICM production system (2025) after migrating Moodle 4.1 to a new host. It was resolved by Bart (Kaliber) following performance analysis and parameter tuning.